Custom model and Transform¶
![]()
This notebook contains the simple examples of custom model and Transform that can be added to the ETNA framework.
Table of Contents
[1]:
import pandas as pd
from etna.datasets.tsdataset import TSDataset
from etna.transforms import DateFlagsTransform, LinearTrendTransform
import warnings
warnings.filterwarnings("ignore")
1. What is Transform and how it works¶
Our library works with the spacial data structure TSDataset. So, before starting, we need to convert the classical DataFrame to TSDataset.
[2]:
df = pd.read_csv("data/example_dataset.csv")
df["timestamp"] = pd.to_datetime(df["timestamp"])
df = TSDataset.to_dataset(df)
ts = TSDataset(df, freq="D")
ts.head(5)
[2]:
| segment | segment_a | segment_b | segment_c | segment_d |
|---|---|---|---|---|
| feature | target | target | target | target |
| timestamp | ||||
| 2019-01-01 | 170 | 102 | 92 | 238 |
| 2019-01-02 | 243 | 123 | 107 | 358 |
| 2019-01-03 | 267 | 130 | 103 | 366 |
| 2019-01-04 | 287 | 138 | 103 | 385 |
| 2019-01-05 | 279 | 137 | 104 | 384 |
Let’s look at the original view of data
[3]:
ts.plot()
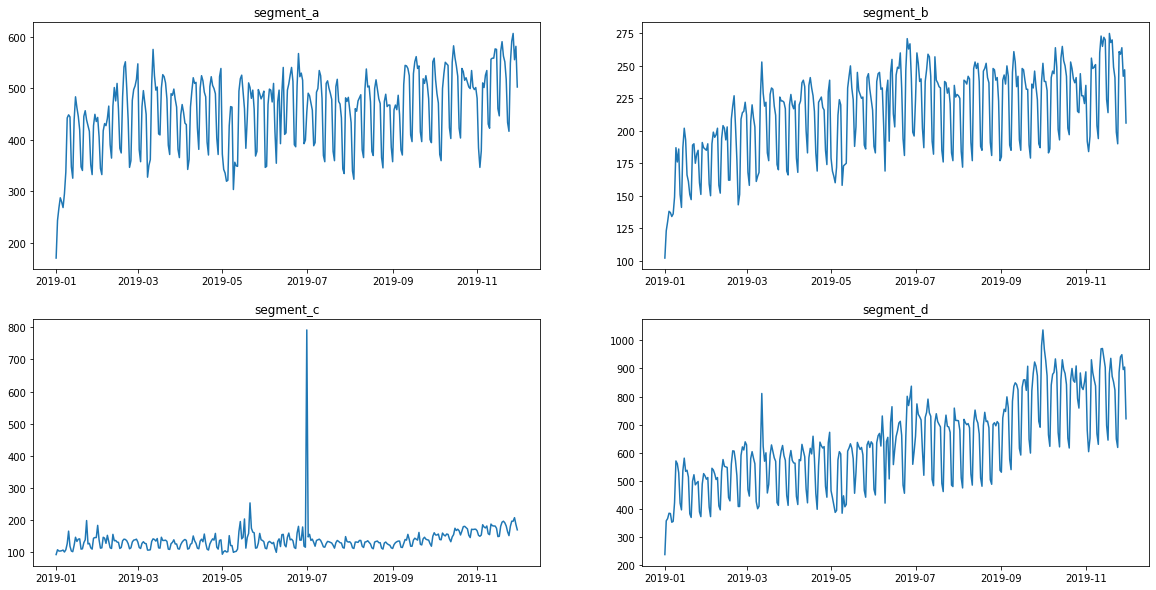
Transform is the manipulation of data to extract new features or update created ones.
In ETNA, Transforms can change column values or add new ones.
For example:
DateFlagsTransform - adds columns with information about the date (day number, is the day a weekend, etc.) .
LinearTrendTransform - subtracts a linear trend from the series (changes it).
[4]:
dates = DateFlagsTransform(day_number_in_week=True, day_number_in_month=False, out_column="dateflag")
detrend = LinearTrendTransform(in_column="target")
ts.fit_transform([dates, detrend])
ts.head(3)
[4]:
| segment | segment_a | segment_b | segment_c | segment_d | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| feature | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target |
| timestamp | ||||||||||||
| 2019-01-01 | 1 | False | -236.276825 | 1 | False | -79.162964 | 1 | False | -26.743498 | 1 | False | -194.070140 |
| 2019-01-02 | 2 | False | -163.575877 | 2 | False | -58.358457 | 2 | False | -11.861383 | 2 | False | -75.292679 |
| 2019-01-03 | 3 | False | -139.874928 | 3 | False | -51.553950 | 3 | False | -15.979267 | 3 | False | -68.515217 |
In addition to the appearance of a new column, the values in the target column have changed. This can be seen from the graphs.
[5]:
ts.plot()
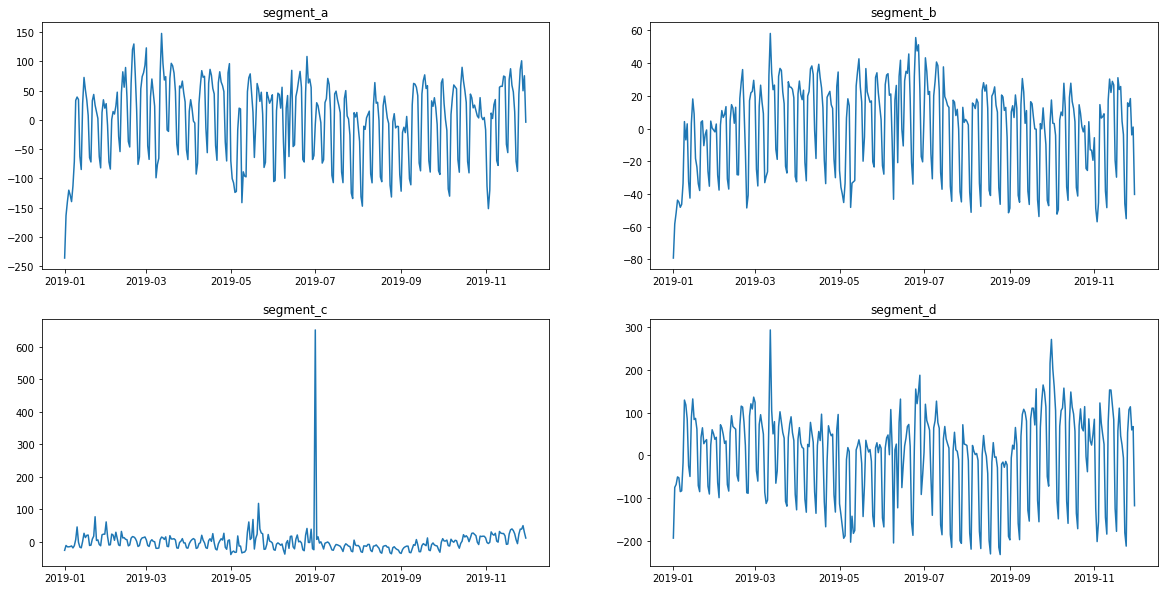
[6]:
ts.inverse_transform()
ts.head(3)
[6]:
| segment | segment_a | segment_b | segment_c | segment_d | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| feature | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target | dateflag_day_number_in_week | dateflag_is_weekend | target |
| timestamp | ||||||||||||
| 2019-01-01 | 1 | False | 170.0 | 1 | False | 102.0 | 1 | False | 92.0 | 1 | False | 238.0 |
| 2019-01-02 | 2 | False | 243.0 | 2 | False | 123.0 | 2 | False | 107.0 | 2 | False | 358.0 |
| 2019-01-03 | 3 | False | 267.0 | 3 | False | 130.0 | 3 | False | 103.0 | 3 | False | 366.0 |
Now the data is back in its original form
[7]:
ts.plot()
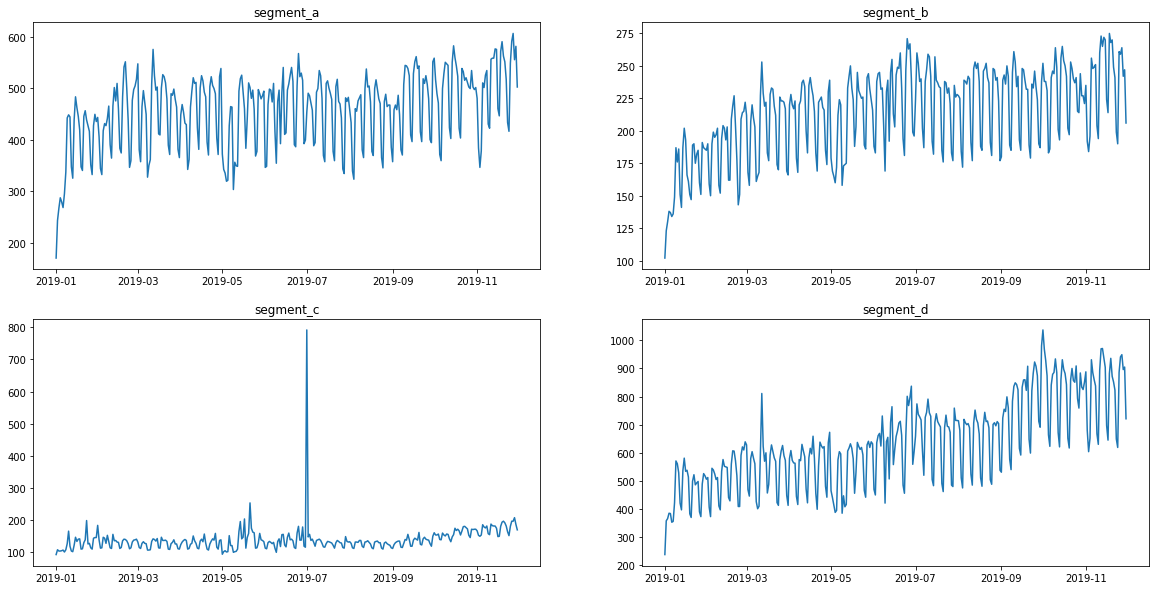
2. Custom Transform¶
Let’s define custom Transform.
Consider a Transform that sets bounds at the top and bottom - FloorCeilTransform
ETNA use PerSegmentWrapper, so it is enough to describe the transformation for one segment and then apply it.
Any Transform inherits from the base class.
[8]:
from etna.transforms.base import PerSegmentWrapper
from etna.transforms.base import Transform
[9]:
# Class for processing one segment.
class _OneSegmentFloorCeilTransform(Transform):
# Constructor with the name of the column to which the transformation will be applied.
def __init__(self, in_column: str, floor: float, ceil: float):
"""
Create instance of _OneSegmentLinearTrendBaseTransform.
Parameters
----------
in_column:
name of processed column
floor:
lower bound
ceil:
upper bound
"""
self.in_column = in_column
self.floor = floor
self.ceil = ceil
# Provide the necessary training. For example calculates the coefficients of a linear trend.
# In this case, we calculate the indices that need to be changed
# and remember the old values for inverse transform.
def fit(self, df: pd.DataFrame) -> "_OneSegmentFloorCeilTransform":
"""
Calculate the indices that need to be changed.
Returns
-------
self
"""
target_column = df[self.in_column]
self.floor_indices = target_column < self.floor
self.floor_values = target_column[self.floor_indices]
self.ceil_indices = target_column > self.ceil
self.ceil_values = target_column[self.ceil_indices]
return self
# Apply changes.
def transform(self, df: pd.DataFrame) -> pd.DataFrame:
"""
Drive the value to the interval [floor, ceil].
Parameters
----------
df:
DataFrame to transform
Returns
-------
transformed series
"""
result_df = df.copy()
result_df[self.in_column].iloc[self.floor_indices] = self.floor
result_df[self.in_column].iloc[self.ceil_indices] = self.ceil
return result_df
# Do it all in one action. Base class requirement.
def fit_transform(self, df: pd.DataFrame) -> pd.DataFrame:
return self.fit(df).transform(df)
# Returns back changed values.
def inverse_transform(self, df: pd.DataFrame) -> pd.DataFrame:
"""
Inverse transformation for transform. Return back changed values.
Parameters
----------
df:
data to transform
Returns
-------
pd.DataFrame
reconstructed data
"""
result = df.copy()
result[self.in_column][self.floor_indices] = self.floor_values
result[self.in_column][self.ceil_indices] = self.ceil_values
return result
Now we can define class, which will work with the entire dataset, applying a transform(_OneSegmentFloorCeilTransform) to each segment.
This functionality is provided by PerSegmentWrapper.
[10]:
class FloorCeilTransform(PerSegmentWrapper):
"""Transform that truncate values to an interval [ceil, floor]"""
def __init__(self, in_column: str, floor: float, ceil: float):
"""Create instance of FloorCeilTransform.
Parameters
----------
in_column:
name of processed column
floor:
lower bound
ceil:
upper bound
"""
self.in_column = in_column
self.floor = floor
self.ceil = ceil
super().__init__(
transform=_OneSegmentFloorCeilTransform(
in_column=self.in_column, floor=self.floor, ceil=self.ceil
)
)
Lets take a closer look.
This is what the original data looks like.
[11]:
ts.plot()
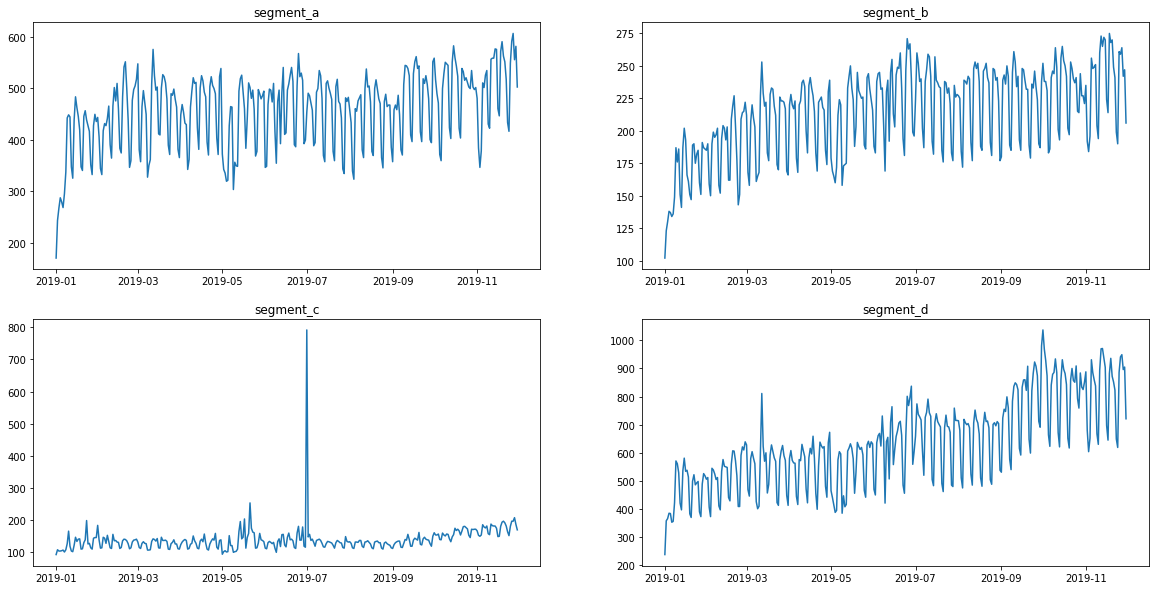
[12]:
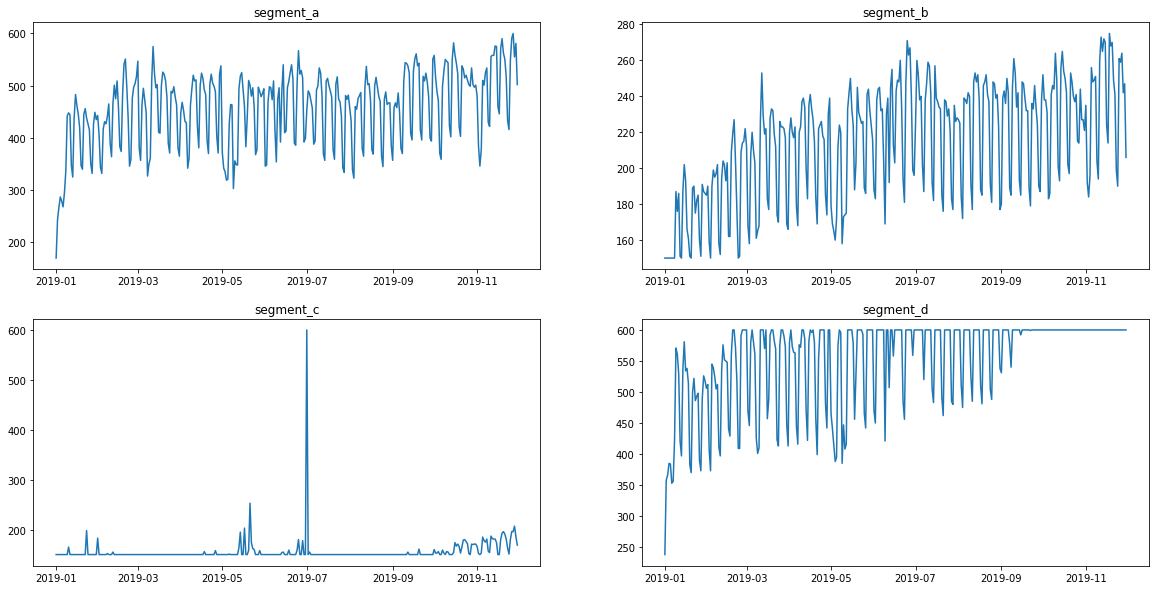
bounds = FloorCeilTransform(in_column="target", floor=150, ceil=600)
ts.fit_transform([bounds])
The values are now limited. Let’s see how it looks
[13]:
ts.plot()
Returning to the original values
[14]:
ts.inverse_transform()
[15]:
ts.plot()
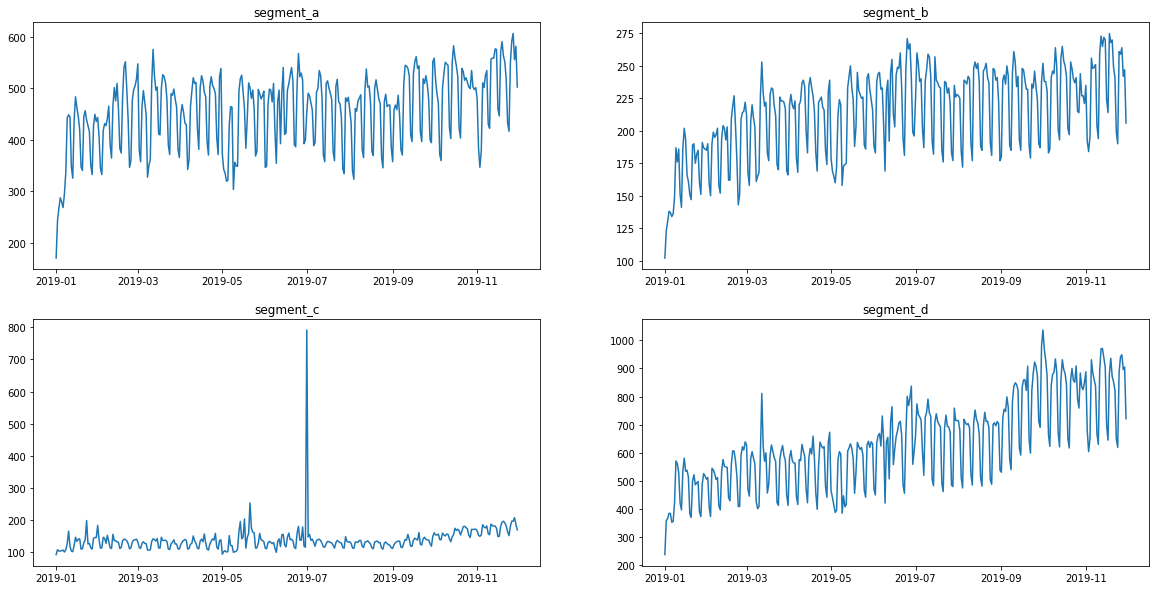
Everything seems to be working correctly. Remember to write the necessary tests before adding a new transform to the library.
3. Custom Model¶
[16]:
!pip install lightgbm -q
if the required module is not in the library, you should add it to the poetry file.
[17]:
from typing import List
from lightgbm import LGBMRegressor
from etna.models.base import BaseAdapter
from etna.models.base import MultiSegmentModel
from etna.models.base import PerSegmentModel
from etna.pipeline import Pipeline
If you could not find a suitable model among the ready-made ones, then you can create your own.
There are two ways for using models.
One model for entire dataset
One model for each segment
We need 2 classes for this options.
First, we need to implement adapter model that connects our library to lightgbm.
[18]:
class _LGBMAdapter(BaseAdapter):
def __init__(
self,
boosting_type="gbdt",
num_leaves=31,
max_depth=-1,
learning_rate=0.1,
n_estimators=100,
**kwargs,
):
self.model = LGBMRegressor(
boosting_type=boosting_type,
num_leaves=num_leaves,
max_depth=max_depth,
learning_rate=learning_rate,
n_estimators=n_estimators,
**kwargs
)
self._categorical = None
def fit(self, df: pd.DataFrame, regressors: List[str]):
features = df.drop(columns=["timestamp", "target"])
self._categorical = features.select_dtypes(include=["category"]).columns.to_list()
target = df["target"]
self.model.fit(X=features, y=target, categorical_feature=self._categorical)
return self
def predict(self, df: pd.DataFrame):
features = df.drop(columns=["timestamp", "target"])
pred = self.model.predict(features)
return pred
def get_model(self) -> LGBMRegressor:
return self.model
One model for each segment. Base class — PerSegmentModel.
All methods are described in the base class. All that remains is to initialize.
[19]:
class LGBMPerSegmentModel(PerSegmentModel):
def __init__(
self,
boosting_type="gbdt",
num_leaves=31,
max_depth=-1,
learning_rate=0.1,
n_estimators=100,
**kwargs,
):
self.boosting_type = boosting_type
self.num_leaves = num_leaves
self.max_depth = max_depth
self.learning_rate = learning_rate
self.n_estimators = n_estimators
self.kwargs = kwargs
model = _LGBMAdapter(
boosting_type=boosting_type,
num_leaves=num_leaves,
max_depth=max_depth,
learning_rate=learning_rate,
n_estimators=n_estimators,
**kwargs
)
super().__init__(base_model=model)
One model for entire dataset. Base class — MultiSegmentModel
[20]:
class LGBMMultiSegmentModel(MultiSegmentModel):
def __init__(
self,
boosting_type="gbdt",
num_leaves=31,
max_depth=-1,
learning_rate=0.1,
n_estimators=100,
**kwargs,
):
self.boosting_type = boosting_type
self.num_leaves = num_leaves
self.max_depth = max_depth
self.learning_rate = learning_rate
self.n_estimators = n_estimators
self.kwargs = kwargs
model = _LGBMAdapter(
boosting_type=boosting_type,
num_leaves=num_leaves,
max_depth=max_depth,
learning_rate=learning_rate,
n_estimators=n_estimators,
**kwargs
)
super().__init__(base_model=model)
Train our model
[21]:
HORIZON = 31
train_ts, test_ts = ts.train_test_split(train_start="2019-01-01",
train_end="2019-11-30",
test_start="2019-12-01",
test_end="2019-12-31")
[22]:
from etna.transforms import LagTransform
from etna.transforms import LogTransform
from etna.transforms import SegmentEncoderTransform
from etna.transforms import DateFlagsTransform
from etna.transforms import LinearTrendTransform
log = LogTransform(in_column="target", out_column="log")
trend = LinearTrendTransform(in_column="target")
seg = SegmentEncoderTransform()
lags = LagTransform(in_column="target", lags=list(range(31, 96, 1)), out_column="lag")
d_flags = DateFlagsTransform(day_number_in_week=True,
day_number_in_month=True,
week_number_in_month=True,
week_number_in_year=True,
month_number_in_year=True,
year_number=True,
special_days_in_week=[5, 6],
out_column="date_feature")
transforms = [trend, lags, d_flags, seg]
[23]:
model = LGBMMultiSegmentModel()
pipeline = Pipeline(model=model, transforms=transforms, horizon=HORIZON)
pipeline.fit(train_ts)
forecast_ts = pipeline.forecast()
Let’s see the results
[24]:
from etna.analysis import plot_forecast
[25]:
plot_forecast(forecast_ts, test_ts, train_ts, n_train_samples=20)
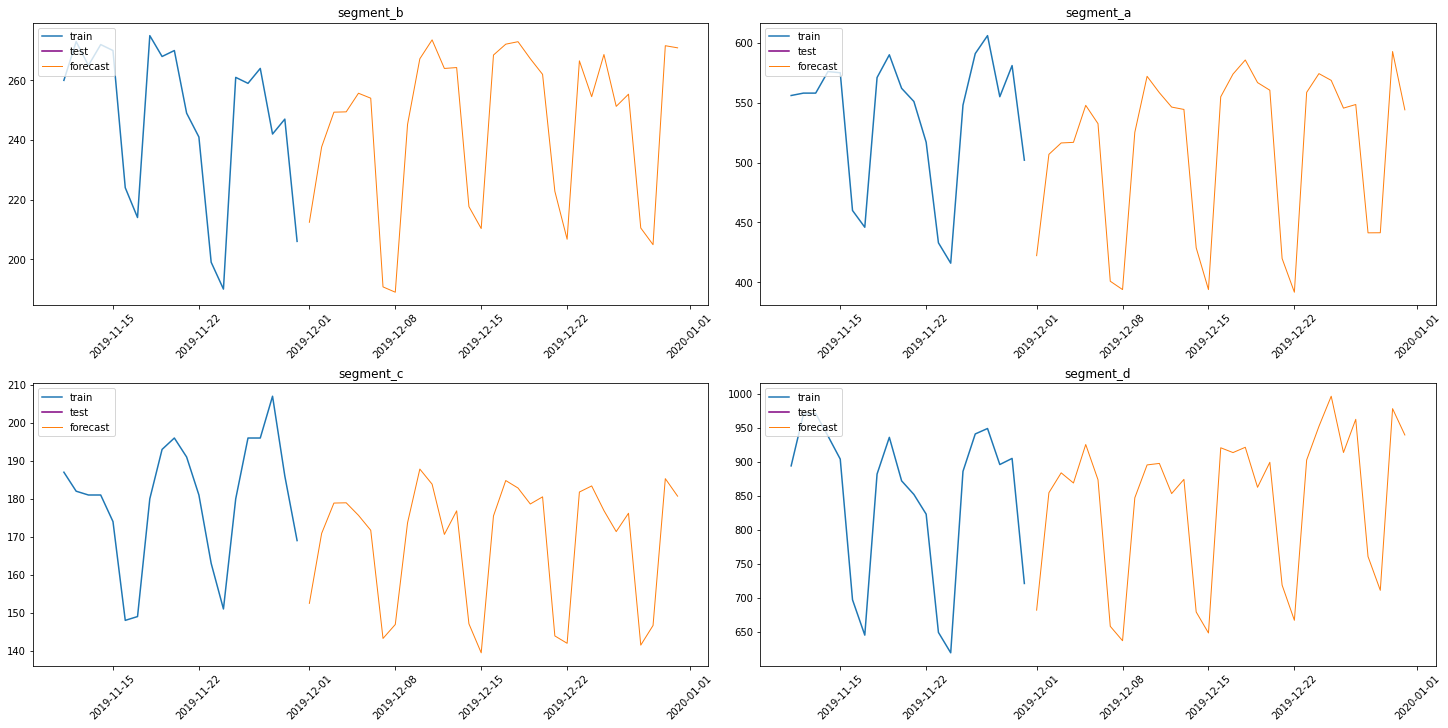
This way you can specialize your task with ETNA or even add new features to the library. Don’t forget to write the necessary tests and documentation. Good luck !